Spring Boot 3.2, VMware by Broadcom and Conference Planning for 2024
Happy Monday and welcome to another edition of the newsletter. If you celebrated Thanksgiving, I hope you had a wonderful holiday filled with family, food, laughter, and love. Even if you're not in the US, I wish the same for you. We had a wonderful Thanksgiving feast in my home as we hosted over 20 people. My wife did an amazing job on putting together a great day filled with amazing food and ambiance. I successfully deep fried my first turkey and did it without burning the house down 🤣

Today, I have a lot to discuss, including Spring Boot 3.2, VMware by Broadcom, and conference planning for 2024.
Spring Boot 3.2
Last week, Spring Boot 3.2 was released, bringing with it a host of exciting new features. If you visit start.spring.io and attempt to create a new project, you will see that the current version is now 3.2. Additionally, you will notice that only Java versions 17 and 21 are supported. This is because Spring Boot 3.0 is based on Java 17, and the latest release includes support for Java 21.
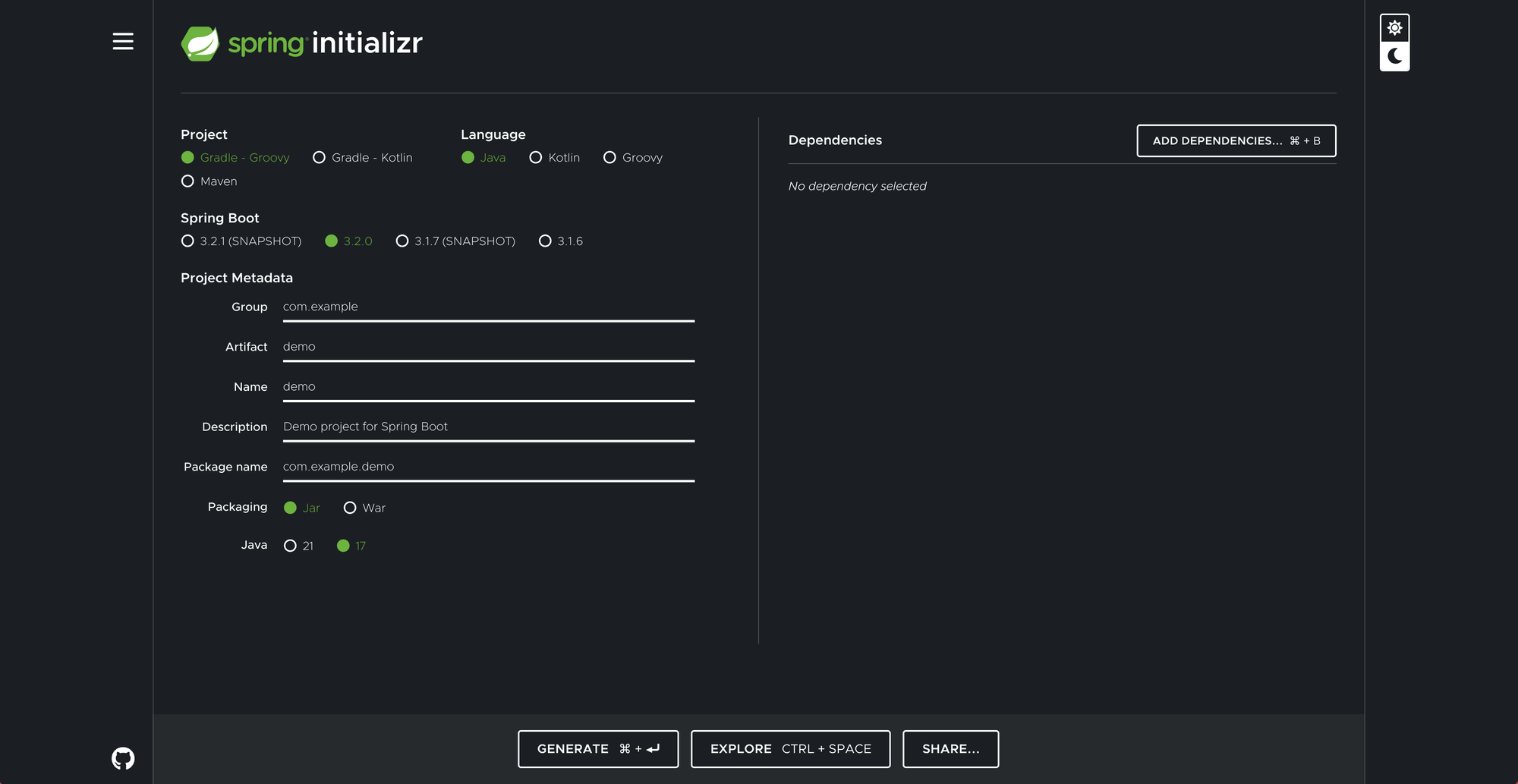
Java 21
Speaking of Java 21, Spring Boot 3.2 introduces support for Virtual Threads. I created a video on Virtual Threads during the preview phase, but I plan on making an updated video soon to cover all the exciting changes in Spring Boot 3.2. To use Virtual Threads, you need to run Java 21 and set the property spring.threads.virtual.enabled to true.
While Project Loom and Virtual Threads are the highlights of Java 21, there are other great features as well. As I start using Java 21, I'm excited to take advantage of all its amazing features. Here are a few of my favorites:
Rest Client
Spring Boot 3.2 includes support for the newRestClientinterface which has been introduced in Spring Framework 6.1. This interface provides a functional style blocking HTTP API with a similar to design toWebClient.
Existing and new application might want to consider usingRestClientas an alternative toRestTemplate. If you want to learn more about the RestClient you can check out the following video I did on it.
JDBC Client
The JDBC Template abstraction has been around since the early stages of Spring. Spring Framework 6.1 introduced a new JDBC Client that gives us a new fluent API for talking to a database. What I love about this is that everything lines up you need longer need to write your own RowMapper which always felt like boiler plate code I didn’t need to be writing and now I don’t. Spring Boot 3.2 adds auto-configuration for a JdbcClient . If you want to learn more about you can check out the following video I did on it.
Spring Boot 3.2 Release Notes
There are many other topics we can discuss regarding Spring Boot 3.2. A great resource to learn about all of this is the comprehensive release notes compiled by the Spring Team. If you want to learn more about Spring Boot 3.2 you can join me and DaShaun tomorrow on Spring Office Hours as we go through everything.
This is also a gentle reminder that Spring Boot 2.7 support officially ends today. If you or your organization needs help upgrading to Spring Boot 3 please feel free to reach out to me.
VMware by Broadcom
VMware is now VMware by Broadcom as the acquisition has closed. A little after I started here, which is almost 2 years the acquisition was announced and 18 months later it has finally closed. I would be lying if I didn’t say it has been a stressful few months.

The uncertainty about my future has been the hardest part. I know a lot of people who left so that they didn’t have to go through it but for me that was never an option. I landed my dream job and I love the people that I work with so I was going to ride this out as long as I could.
I’m very thankful for my time at VMware and I happy to say that I will continue to do what I love at VMware by Broadcom 🥳 I love the community that I serve and if there is anything I can do to help please don’t hesitate to reach out. I’m excited about the future and have already started putting some big plans together for the new year.
While that is the good news for me, acquisitions are never easy on everyone. I know many people are currently finding out there fate and my thoughts are with them. We have some of the smartest people I have ever had the joy of working with and I hope it works out here but If it doesn’t I know they will move on to bigger and better things. 💔
Conference Planning for 2024
If you aren't new around here you already know that I am a huge fan of Notion and being organized. I have a database in Notion where I keep my list of possible conferences by year. I have begun preparing talks and submitting CFPs for conferences in 2024 and this is what my current list looks like
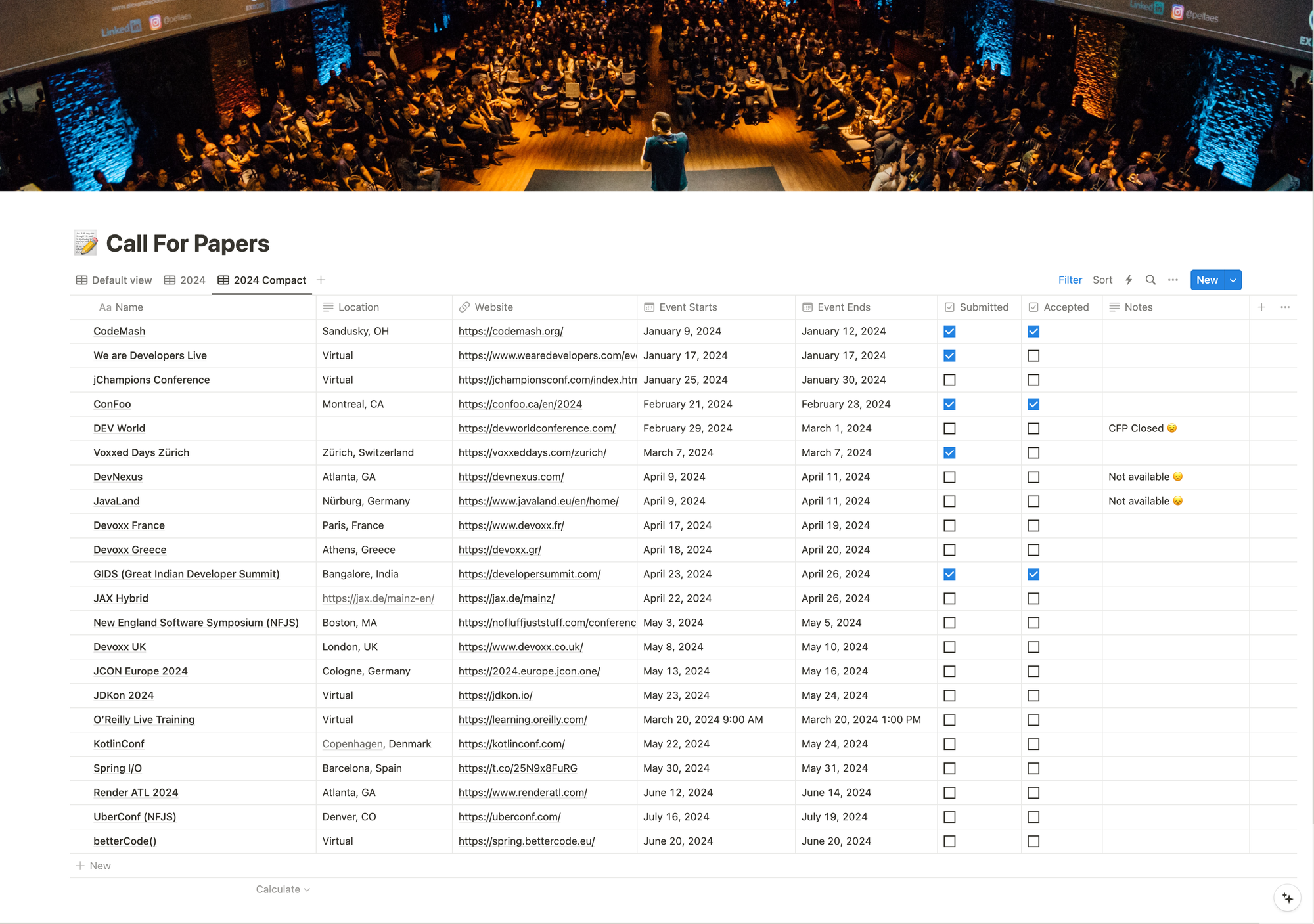
Last week I found out that I got accepted to GIDS and I am beyond excited about attending and speaking here. I have always wanted to visit India and now I will get my opportunity in April.
https://twitter.com/developersummit/status/1726384860959215665
If you are ever curious about upcoming speaking engagements you can check out my speaking page on my website.
Around the web
🎙 Podcasts
I really enjoyed this podcast by Adam Bein on why Kotlin is better than Java. This is a very timely episode as I just put out a poll on Twitter last week asking all of you If I should learn Kotlin.
✍️ Quote of the week
"Gratitude is not only the greatest of virtues, but the parent of all the others." - Marcus Tullius Cicero
🐦 Tweet
https://twitter.com/therealdanvega/status/1726962300484296726
Until Next Week
I hope you enjoyed this newsletter installment, and I will talk to you in the next one. If you have any links you would like me to include please contact me and I might add them to a future newsletter. I hope you have a great week and as always friends...
Happy Coding
Dan Vega
[email protected]
https://www.danvega.dev